背景
系统里使用redis里watch-multi-exec一种CAS机制来控制并发的更新操作,目前使用的场景:
- chat里的房间信息(e.g. 成员变化)
- session系统的会话信息,涉及到的更新场景较多(e.g. 会话状态变化、聊天时间、评价、虚商等)
- mcc里员工信息(e.g. 工作状态、服务的会话)
- 但一直以来,都是开发人员自行维护了单机redis来实现上面一套,存在一定的风险,而公司运维维护了一套在底层storage上有一层类似codis的代理中间件,watch/multi/exec事务有关的命令不支持。
redis分布式锁
实现细节
通过setNx命令
针对一个key进行加锁解锁操作,需要是相同的value,value保证是唯一
需要过期时间避免死锁
lua脚本实现原子操作
- 加锁
1 | /** |
- 解锁
1 | /** |
这里是通过redis的map数据结构
key:/lock/xxx
field:tid-uuid
value:state(重入次数)
基于主从、读写不分离
redis加锁后的代码执行时间可能超出获取锁的过期时间,导致不安全的情况。redisson里面会有一种watchDog机制来续租锁的保持情况,这里使用kafka多层时间轮的实现来进行高效的延迟任务执行。
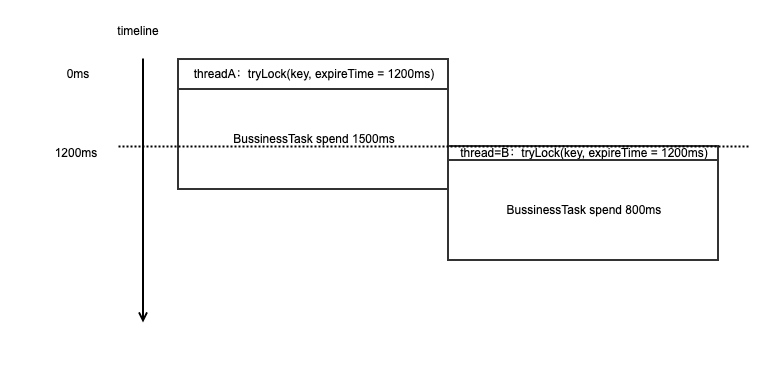
上图简单说明了,如果过期时间设置不当或者出现stw或者其他低优先级的进程调度,可能会出现多个线程同时得到锁的非安全场景。

在获取锁时,包装一个delay = 1/2 * leaseTime的续租任务加入到timingwheel上
当时间过了1/2 * leaseTime,timingwheel的指针扫到该续租任务,执行。访问redis,为锁住的key重设leaseTime过期时间。
1 | /** |
续租任务执行完成后,则继续将其续租任务加入到timingwheel中,否则取消任务
当业务执行完毕后,进行解锁,并取消任务(如果存在任务)
弊端
- 基于master-slave的部署方式,client1从master获取锁后,master意外宕机,此时进行了主从切换,但slave里还未来得及同步到之前master节点锁的获取情况,client2此时尝试获取锁,也能获取锁,这种是不安全的情况。
- 我司pub/sub命令在线上被禁用,无法通过这种天然的通知机制来传递解锁事件(暂时不想加其他中间件增加复杂度),唤醒等待锁的线程;目前在实现上使用了间隔一段时间(根据ttl和请求的剩余timeout)去请求锁,超过最大timeout则直接失败,存在一定cpu资源的浪费
代码结构
Redlock
为了解决上述master-slave切换导致的不安全场景,官方Redlock的实现,首先是部署redis-cluster协议的集群,client依次向集群每个节点去请求锁(setNx),当获取(1 / 2 * N + 1)的锁时,才算认为获取锁成功。
也存在一定的问题,https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
网络延时边界,即假设数据包一定能在某个最大延时之内到达
进程停顿边界,即进程停顿一定在某个最大时间之内
时钟错误边界,即不会从一个坏的 NTP 服务器处取得时间
etcd、zk
- etcd里每个 key 带有一个 Revision值,etcd 每进行一次事务对应的全局 Revision 值都会加一,因此每个 key 对应的 Revision 属性值都是全局唯一的。通过比较 Revision 的大小就可以知道进行写操作的顺序。多个请求方根据 Revision 值大小依次获得锁。
- zk也是类似的,生成自增的临时节点,获取锁时判断自己创建的子节点是否为当前子节点列表中序号最小的子节点。
非要优秀,适合CP场景,而我们目前线上跑的用redis那套CAS代码实现上,允许更新失败,聊天会话业务快一点更适合redis来实现,不用那么准确。